FallTalk is an advanced AI-driven audio generation and cloning tool. Leveraging Retrieval-based-Voice-Conversion (RVC) and integrating with multiple open-source solutions, FallTalk offers the best audio quality at no cost. You will be hard to find a better audio generator paid or otherwise today.
This code and the accompanying FallTalk AI models are provided subject to the terms and conditions of the End User License Agreement (EULA) of Zenimax Media, Inc., the original rights holder of the Fallout franchise. By using this code or the FallTalk AI models, you agree to comply with the following permitted and prohibited uses, as well as all terms outlined in the Zenimax Media EULA.
By accessing and using the FallTalk, you hereby agree to the following terms and conditions:
Public Disclosure of AI Synthesis: You are obligated to clearly inform any and all end-users that the speech content they are interacting with has been synthesized using the FallTalk AI models. This disclosure should be made in a manner that is prominent and easily understandable.
Permitted Use: You agree to use the FallTalk AI models exclusively for the following purposes:
• Personal Use: Utilizing the FallTalk AI models for personal, non-commercial projects and activities that do not involve the distribution or sharing of synthesized speech content with others. • Research: Conducting academic or scientific research in the field of artificial intelligence, speech synthesis, or related disciplines. • Non-Commercial Mod Creation: Developing and distributing modifications (mods) for the game Fallout 4 that are available to the public free of charge.
Prohibited Use: You are expressly prohibited from using the FallTalk AI models for any commercial purposes, including but not limited to:
• Selling or licensing the synthesized speech content. • Incorporating the synthesized speech into any commercial product or service. • Creating or distributing any pornographic or adult material.
Compliance with Laws and Regulations: You agree to comply with all applicable laws, regulations, and ethical standards in your use of the FallTalk models. This includes, but is not limited to, laws concerning intellectual property, privacy, and consumer protection. We assume no responsibility for any illegal use of the codebase.
Acknowledgment of Rights Holder: Zenimax Media, Inc. is the original rights holder of the Fallout franchise and all related intellectual property. This code and the FallTalk AI models are provided for the specific purposes outlined above, and any use outside of these parameters may violate Zenimax Media's intellectual property rights.
https://bethesda.net/data/eula/en.html
File credits
These are the open source tools used to help make FallTalk:
Erew123 creator AllTalk: This project was originally a fork of AllTalk, all the work hes done is great. Getting deepspeed installed, rvc, and other features would not be possible without him.
BSA Browser CLI: Allows us to extract the reference audio from Fallout 4
Untrained models with no RVC work with custom generation
Version 1.1.8
Fix bug with voicecraft downdowns selecting the first instance of a word
add new noise reduction method that is faster
support flac and mp3 noise reduction
always save wav files as 44100 PCM 16 to speed up LIP and FUZ generation
Bulk RVC now keep sub directories
Version 1.1.7
fix broken lip generation
Version 1.1.6
Added legacy elevenlabs voices
fixed custom models deletion
fixed custom references not loading
Version 1.1.5
Rewrote RVC to use warm up and cache
This makes it about 85% faster after the first use.
Bulk RVC now goes from 12 hours to 2 hours for protagonist
Switched to latest FFMPEG using SoX for resampling, which is faster and better
Version 1.1.4
Improvements to RVC loading to reduce CPU
RVC by single file added
Improved RVC gui
Version 1.1.3
Reduced size by another 1GB. Now only 2.17GB!
Fix for hugging face cache issue
Version 1.1.2
Bug Fixes
Clean Button to try and recover VRAM
Smaller Display Scaling
More Music and Audio Control
SongStarter Model added
Ability to move huggingface cache. This should help with the "file downloaded but does not match" error some people get
Version 1.1.0
LIP and FUZ creation, with any function or bulk method
Custom Model Support: Train or download a model and you can use it instantly
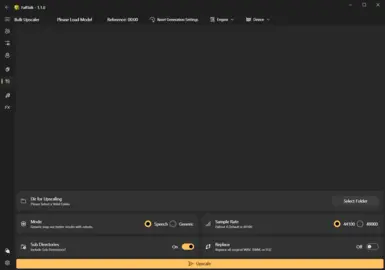
Bulk RVC: Want to replace the main character? Do it with one simple click, and suddenly Nate now sounds like a super mutant, a synth, or much more. Converts entire folders and optionally creates lips and fuz
Bulk Denoiser: Ever hear a mod that has custom audio, but clearly is lower quality and static? The AI denoiser isolates the audio and upscales the voice at the same time.
Bulk Upscaler: take low quality sound effects and make them sound high def and crisp
Music Generation: Perfect for creating background music or audio jingles. Includes a melody cloning feature using any reference audio. Not trained on any audio... yet. Trained using creative commons sourced training data.
Sound FX Generation: Create Sound effects on demand, trained using creative commons sourced data.
Version 1.0.4
Bulk Generation Added
Version 1.0.3
Now will generate lip/fuz files via: https://github.com/Nukem9/FaceFXWrapper
Version 1.0.2
removed files that caused some users issues.
Version 1.0.1
reupload
Version 1.0
First Release
Introduction:
Hello and Welcome to FallTalk, the Open Source Text to Speech (TTS), Voice Cloning, Audio Generation, and Audio Processing Software for Fallout 4. So, why did I create this? Originally, this began as a fun little project to understand how AI works, which could further my career as a software engineer. One day while playing Fallout 4, I encountered a mod with absolutely terrible AI voices. This sparked an idea: what if I combined my project to understand AI and provided the community with a way to create better AI voices?
The main question I've been asked so far is: Why create this when ElevenLabs and xVASynth already exist? I believe the audio quality generated by this tool can be as good as ElevenLabs, and sometimes even better. While it doesn't have the full range of controls like pausing and emotion, since I am not using tortoise tts, selecting a good reference file can give great results. Regarding xVASynth, I think this tool offers a more user-friendly solution for the average person, focusing on convenience.
This new tool will allow you to accurately clone voices from various characters, including the Eyebot, Polymer Labs Announcers, Mr. Gutsy, Liberty Prime, and more. Really, it can accurately clone every voice, from the elevator sounds to the protagonist. These are bold claims, and I have provided audio samples below for your evaluation.
Not only that, it offers an whole host of audio related features for creators to use:
LIP and FUZ creation, with any function or bulk method
Custom Model Support: Train or download a model and you can use it instantly
Bulk RVC: Want to replace the main character? Do it with one simple click, and suddenly Nate now sounds like a super mutant, a synth, or much more. Converts entire folders and optionally creates lips and fuz
Bulk Denoiser: Ever hear a mod that has custom audio, but clearly is lower quality and static? The AI denoiser isolates the audio and upscales the voice at the same time.
Bulk Upscaler: take low quality sound effects and make them sound high def and crisp
Music Generation: Perfect for creating background music or audio jingles. Includes a melody cloning feature using any reference audio. Not trained on any audio... yet. Trained using creative commons sourced training data.
Sound FX Generation: Create Sound effects on demand, trained using creative commons sourced data.
This tool does not contain any assets from Fallout 4, but they were used to train the models. The tool will look for your Fallout 4 directory to use reference audio files.
But Why?
Well, once the gears go going in my head, I had tons of ideas on how to use the generated but no tool to do it well enough. Here are just a few ideas that got me started:
Use the robot voices in mods like the fallout 3 remakes. Welcome to Megaton.
Make a communist Mr Gutsy reprogrammed.
Alternate story where liberty prime is reprogrammed
Expand on the vault tech sales man, adding a quest to vault tech HQ. Maybe even full companion
Adding voices to dialog options that miss them.
Expand Player Comments and Head Tracking, right now they only ever say a few phrases. Gets really repetitive. Maybe also make it dynamic, so the protagonist says things like "ugh more radroaches" etc etc.
If anyone wants to make something on that list with me, hit me up.
Disclaimer of Use:
This code and the accompanying FallTalk AI models are provided subject to the terms and conditions of the End User License Agreement (EULA) of Zenimax Media, Inc., the original rights holder of the Fallout franchise. By using this code or the FallTalk AI models, you agree to comply with the following permitted and prohibited uses, as well as all terms outlined in the Zenimax Media EULA.
By accessing and using the FallTalk, you hereby agree to the following terms and conditions:
Public Disclosure of AI Synthesis: You are obligated to clearly inform any and all end-users that the speech content they are interacting with has been synthesized using the FallTalk AI models. This disclosure should be made in a manner that is prominent and easily understandable.
Permitted Use: You agree to use the FallTalk AI models exclusively for the following purposes:
• Personal Use: Utilizing the FallTalk AI models for personal, non-commercial projects and activities that do not involve the distribution or sharing of synthesized speech content with others. • Research: Conducting academic or scientific research in the field of artificial intelligence, speech synthesis, or related disciplines. • Non-Commercial Mod Creation: Developing and distributing modifications (mods) for the game Fallout 4 that are available to the public free of charge.
Prohibited Use: You are expressly prohibited from using the FallTalk AI models for any commercial purposes, including but not limited to:
• Selling or licensing the synthesized speech content. • Incorporating the synthesized speech into any commercial product or service. • Creating or distributing any pornographic or adult material.
Compliance with Laws and Regulations: You agree to comply with all applicable laws, regulations, and ethical standards in your use of the FallTalk models. This includes, but is not limited to, laws concerning intellectual property, privacy, and consumer protection. We assume no responsibility for any illegal use of the codebase.
Acknowledgment of Rights Holder: Zenimax Media, Inc. is the original rights holder of the Fallout franchise and all related intellectual property. This code and the FallTalk AI models are provided for the specific purposes outlined above, and any use outside of these parameters may violate Zenimax Media's intellectual property rights.
https://bethesda.net/data/eula/en.html
Support
All the models and software have been trained from my personal computer. This is not exactly quick, so I would love any and all support. From training new models, testing, submitting bugs, or making pull request. Also being able to get a 4090 would go a long way for training bigger models.
I used the same reference audio to generate the samples, and used the same prompts. I think its clear that this is just a lot better than the competition.
GPT SoVITS Top P 1, Top k: 15, Temp 0.5: You were right, Nick, Kellogg did have my son. But that wasn't all. He was working with the Institute. He. he, gave them Shaun.
ElevenLabs: <sad>: You were right Nick. Kellogg did have my son. But that wasn't all. He was working with the Institute. He... he gave them Shaun.
Note: I really like how it changes "my" to "me" and so forth to match her accent
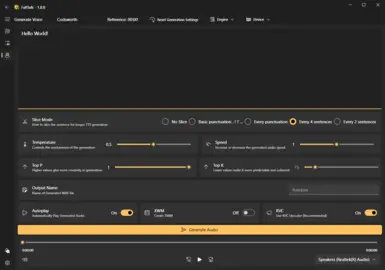
How to Use:
The first step is to download and install Microsoft Visual C++ 2010 Redistributable if you dont have it already. This is needed to extract the audio from Fallout 4.The goal for the app was to make it easy to understand, but lets break down a few key terms:
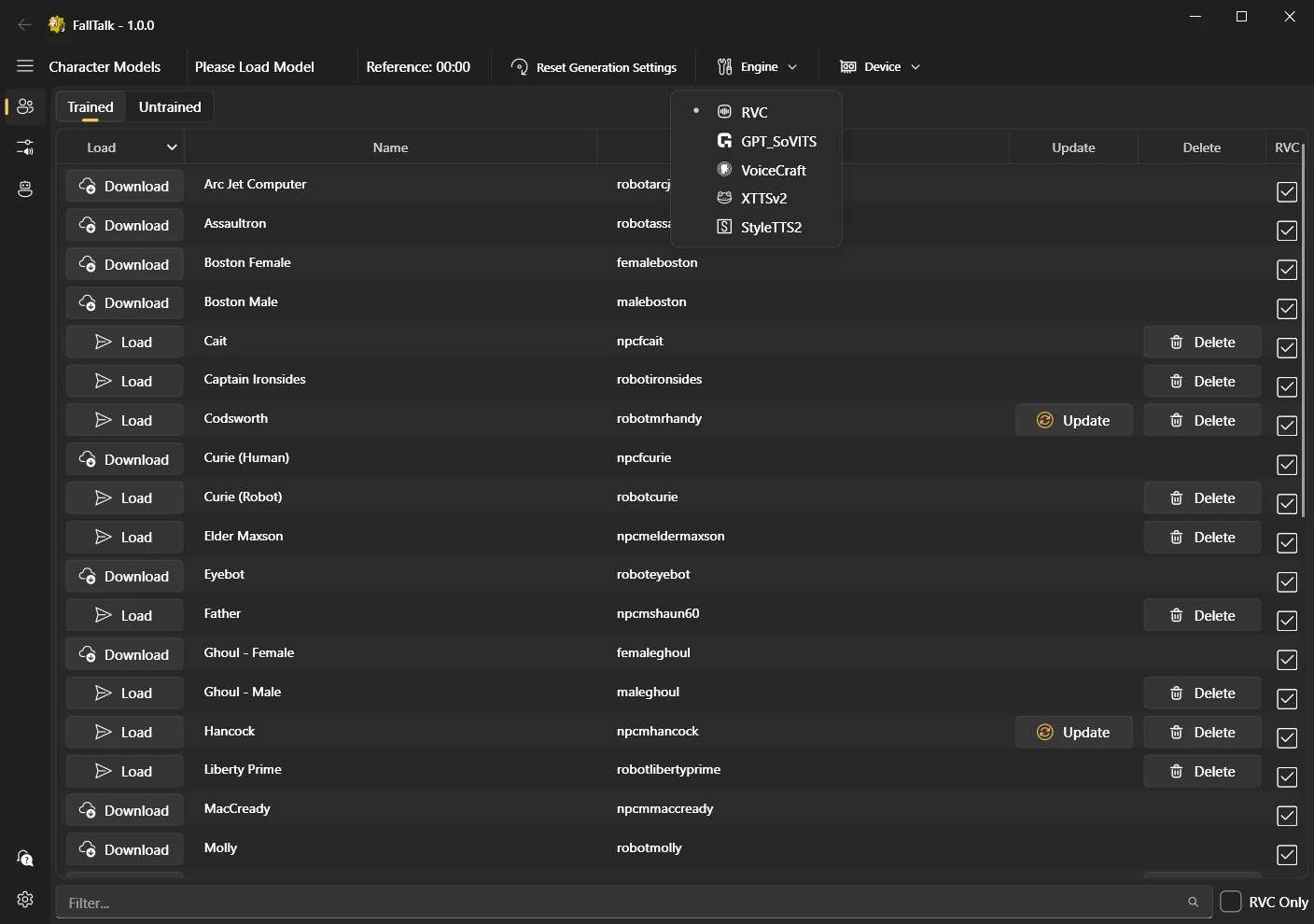
Engine: This is the back end open source engine that can be used to generate the audio. You can quickly change engines by selecting one from the drop down bar about
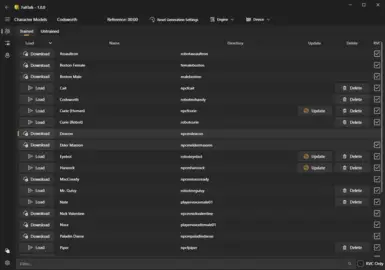
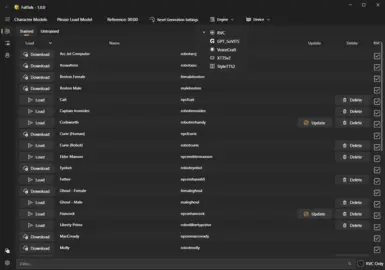
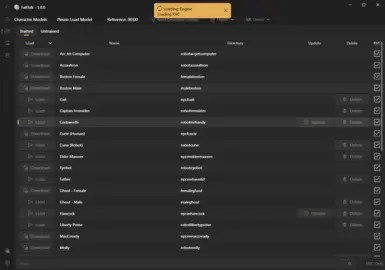
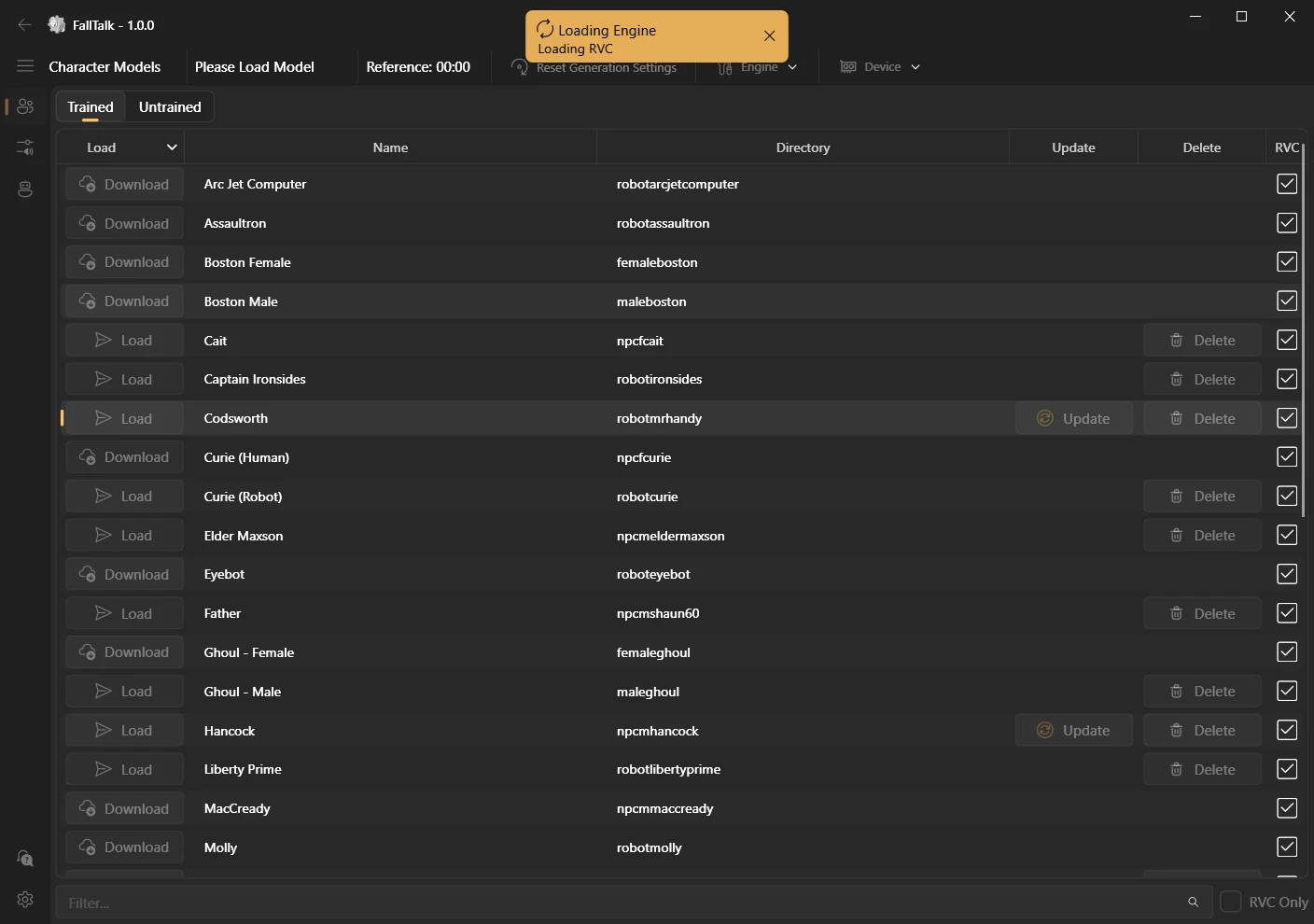
Model: A "model" is a file that contains the data the AI needs to generate the voice. In the FallTalk app, we call them "Characters" for simplicity. Characters can be downloaded, updated, or deleted from the main selection panel. an "untrained" character means that the engine will do its best job to make the voice, but it was not specifically trained on that character. Even when untrained on an engine, you can get good results if the character has a RVC model.
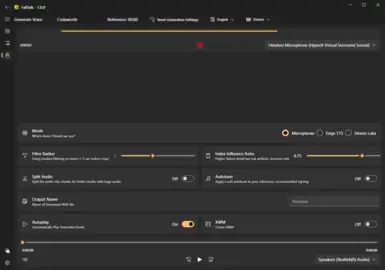
Device: You can generate using GPU or CPU to make the voice. CPU is great because it allows you to run without a NVIDIA GPU, or save resources when playing games.
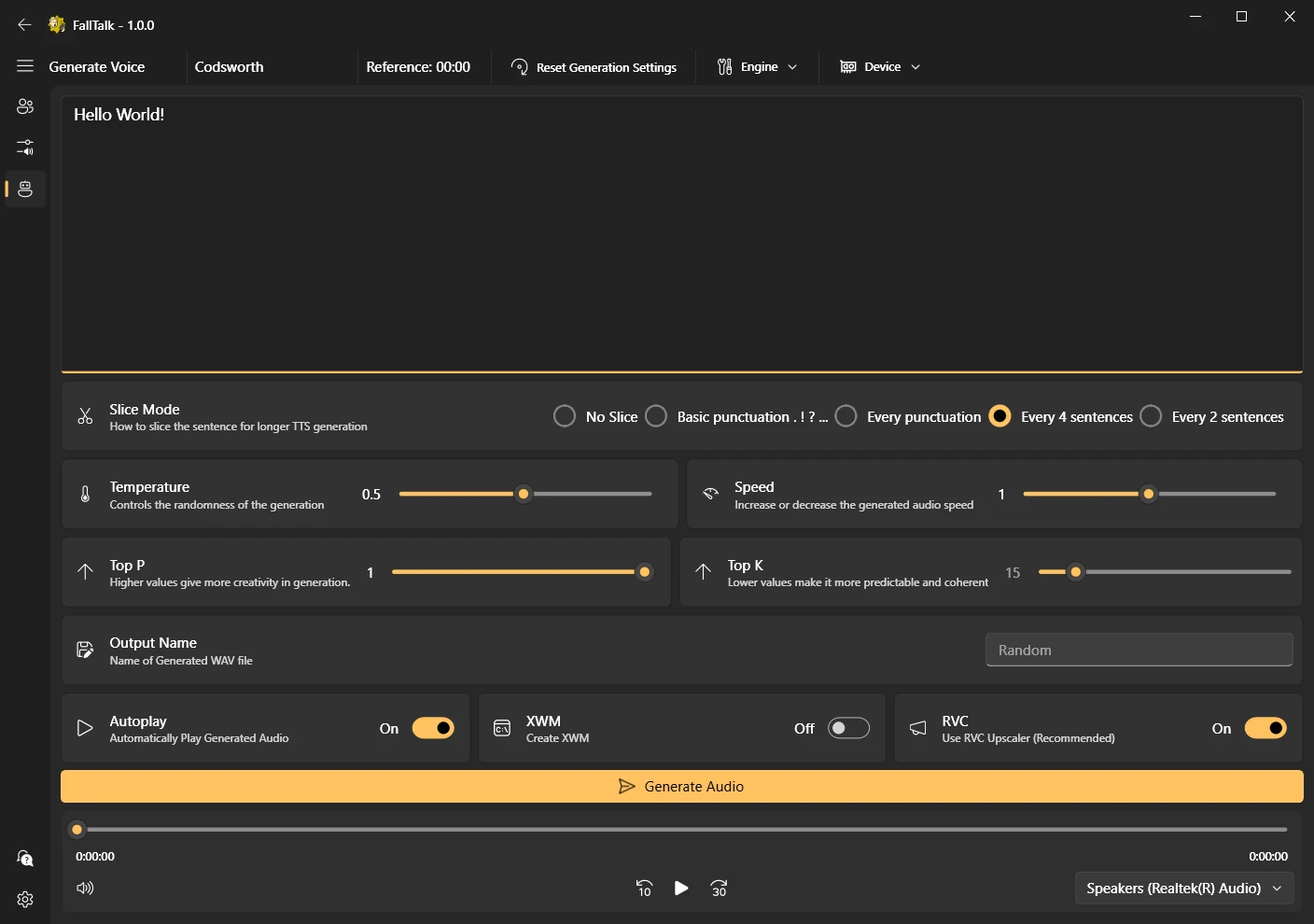
RVC: Retrieval-based-Voice-Conversion is the secret sauce. You can use RVC your microphone on any of the models to turn you into that character. The issue comes when you are the opposite generate, which is why we have the other TTS engines. After the TTS generates audio, we can apply the RVC model on top of the generated audio. Think of it as an audio upscaler when used this way, it just makes the audio sound better.
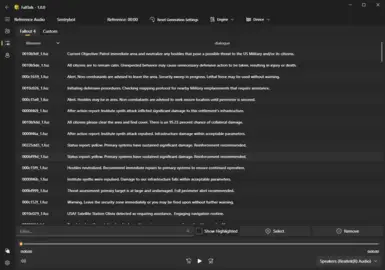
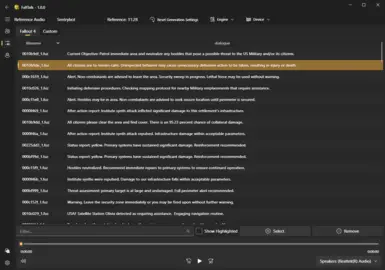
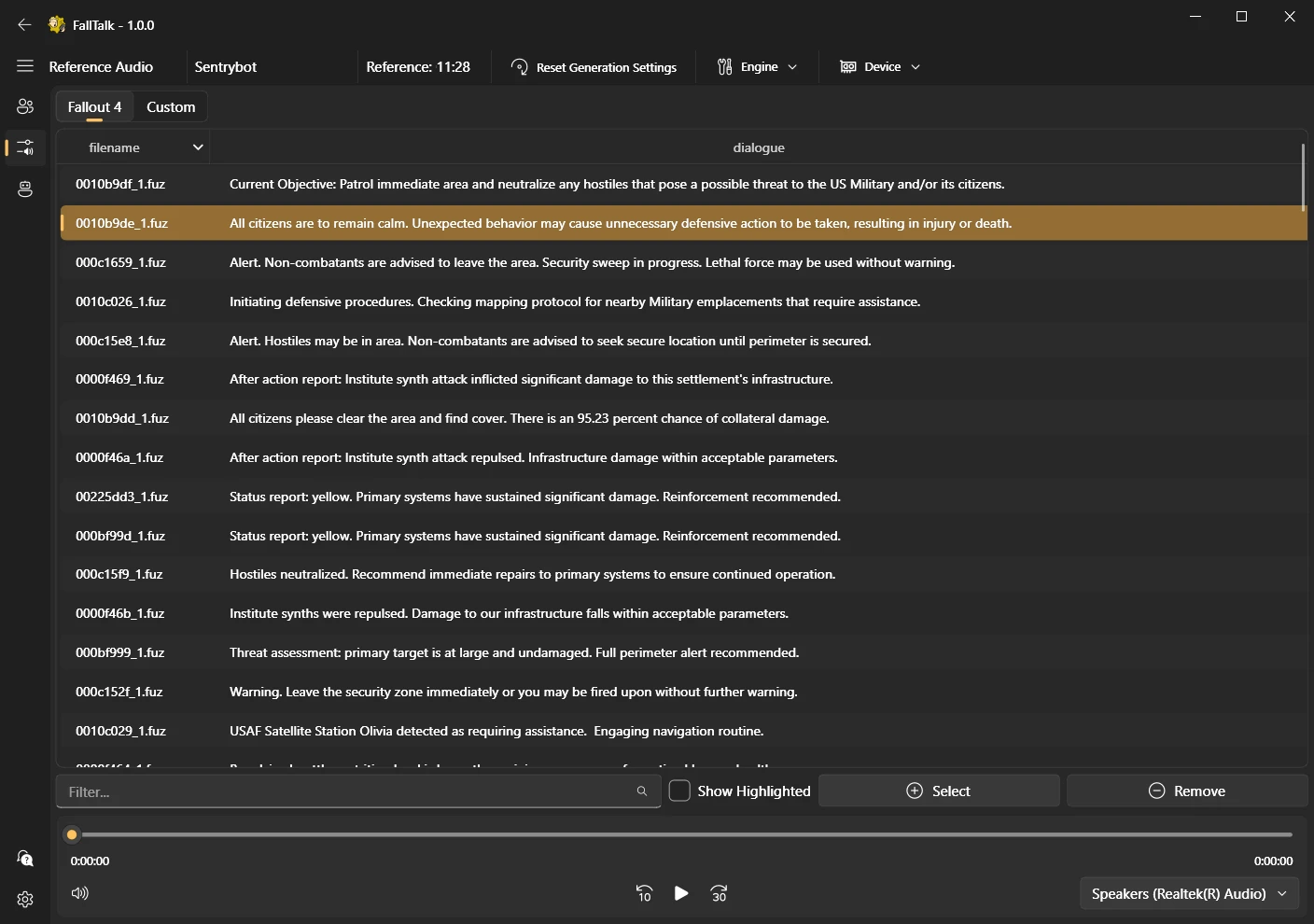
Reference Audio: Reference audio is a sample of voice used by TTS models to mimic or clone specific vocal characteristics during audio generation. Basically, it tries to match the speed, cadence and overall sound of the reference piece. If you pick a reference audio that is a whisper for example, it will greatly change the generated audio. You can select multiple reference audio files.
Each engine has its own requirements for reference audio:
GPT SoVITs (Fine Tuned): Minumum of 1 second of reference audio, but recommneded at least 3. Selecting Multiple references can lead to a better result, assuming they all sound similar.
GPT SoVITs (Untrained): 5-10 seconds. More than 10 seconds can lead to hallucinations.
VoiceCraft: 3-16 seconds. Can work with longer, but can consume too much VRAM.
XTTSv2: 10-15 seconds. Can give back hallucinations with less than 10 seconds, but does sometimes work. Selecting Multiple references can lead to a better result.
StyleTTSv2: 5-10 seconds.
Why did I implement so many engines? Well, because they all have strengths and weakness.
RVC: Voice Cloning using your own voice! This allows you to achieve better results in some cases, as you can mimic the original cadence and speech patterns. It's basically magic.
GPT SoVITs: Extremely fast and easy to train, making it a great all-rounder. Made from the same team as RVC so they work well together.
VoiceCraft: Offers something nothing else does: Audio Editing. This allows you take an existing audio file and tweak it slightly. Want to replace "minutemen" with "NCR", well this is the model to do it. Requires a powerful graphics card to run.
XTTSv2: Offers decent quality, though it may sometimes lack emotion. It excels at generating large amounts of text, making it ideal for narration or long speeches.
StyleTTSv2: Incredibly fast and, as the name suggests, is designed to mimic the tone and style of reference audio. It is often considered the best in the text-to-speech space, but requires a high-end GPU like the RTX 4090 (or two) for fine-tuning a voice. I added it mostly because I want to train it in the future.
The FallTalk program has the framework to add or remove more engines as needed. The only real limit is making sure everything runs on the same python versions. Tips and Tricks:
Text Length: If you want to generate small phrases, sometimes you will need to "pad" your prompt with extra text. This often happens if the generated audio is shorter than the reference audio. So you can try and generate multiple phrases at once, or just put some generic padding phrase.
Reference Audio: Be sure to try multiple reference audios to get a different effect. They can change speed, rhythm, emotion and much more.
Trial And Error: Not happen with how something sounds? Move a slider and regenerate. Rinse and repeat until you get sometime that matches what you are targeting more closely. Mess up and its gibberish? Just reset the settings.
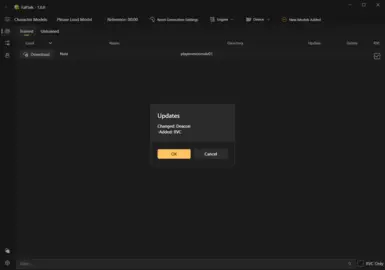
Updates: New models may be released that are better or trained more thoroughly than what was initially released. The main character page will have an update button, and with a single click you can download the new model. Also, as new versions of the apps are released, you will be notified in the main toolbar, but these cannot be auto downloaded at this time.
Laughing / Emotions: Some of the engines will respond correctly if you do this things like "haha" "hmm" "heh" etc. Especially if its in your reference audio.
Getting Started:
The easiest way to get started is by using RVC with a microphone or by employing GPT SoVITS as the text-to-speech engine. GPT SoVITS is the default engine, as it is very easy to fine tune for all the voices and combined with RVC gives amazing results. All settings have been configured to sensible defaults, allowing you to customize them as desired.
Upon launching the application for the first time, you will be required to accept a disclaimer of use. Following this, the app will attempt to locate your Fallout 4 installation. If unsuccessful, you will receive a prompt to navigate to the settings and specify the Fallout 4 installation path, which should be the directory containing the Fallout 4 executable. Note that this step is necessary for all text-to-speech engines except RVC. If you plan to use RVC exclusively, you can opt to not be reminded again.
To begin, let's switch the engine to RVC. Click on the engine dropdown menu and select RVC. This action will initiate the download and installation of RVC, a process that may take a minute or so. Subsequent selections will be significantly faster.
You should now see all of the trained models. You will need to download any from the cloud that you want to use, which is dead simple, just click the download button:
After your model is downloaded, click the "Load" button to load the model into RVC. You will be giving a small loading screen and then automatically moved to the recording page.
And that's it! Make sure the correct recording device is selected and hit the record button. Once you are happy, click the button again to stop the recording and sit back and wait.
Want to change the character? Just go back to the characters screen and hit load.
If you instead want to use another engine like GPT_SoVITS, you will instead be moved to the "Reference Audio" page. The total seconds of reference audio selected is shown in the top menu bar, and the selected references are highlighted for you.
Once you are happy with your references, go to the text to speech generation page, the Robot icon.